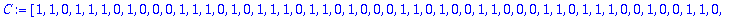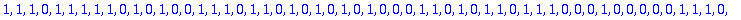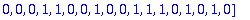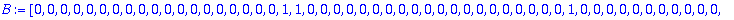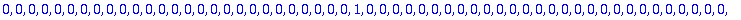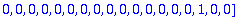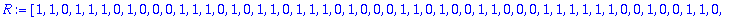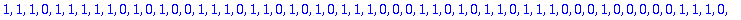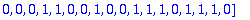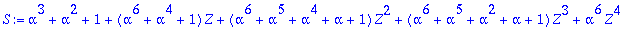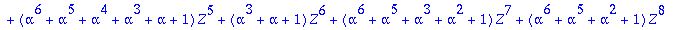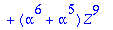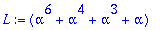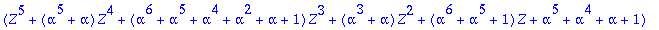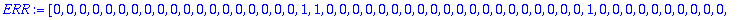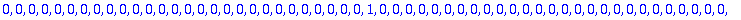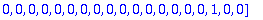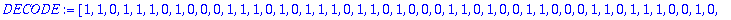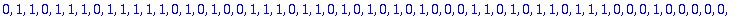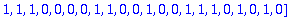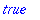CODES BCH
Le but de cette feuille est de fabriquer un code BCH (binaire primitif), et de faire tourner son algorithme de décodage basé sur l'algorithme d'Euclide. La référence recommandée est le livre de Demazure : Cours d'algèbre, éditions Cassini, chapitre 9.
Tous les calculs se font mod 2. Il est conseillé de consulter l'aide de Maple sur "mod" si l'on ne sait pas comment ça fonctionne.
Création du code. Corps engendré par les racines
n
-èmes de l'unité sur
F
_2
On fixe la longueur
n
du code. L'entier
n
est de la forme 2^
r
-1.
Choisir
r
pour fixer la longueur
n
du code
.
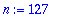
Un mot
a_
1
...a_n
(codé comme un liste) est identifié à l' élément du quotient
F
_2[
X
]/(
X
^
n
-1) représenté par le polynome
a
_1
X
^{
n
-1} + ... +
a
_
n
(N.B. : Demazure écrit le polynome dans l'ordre des puissances croissantes).
Deux procédures tres simples permettent de passer du mot au polynome et vice-versa.
| > |
Pol:=proc(M,n,X)
local k;
add(M[k]*X^(n-k), k=1..n);
end;
|
![Pol := proc (M, n, X) local k; add(M[k]*X^(n-k),k = 1 .. n) end proc](imaBCH/DecBCH2.gif)
| > |
Mot:=proc(P,n,X)
local i;
[seq(coeff(P,X,n-i),i=1..n)];
end;
|
![Mot := proc (P, n, X) local i; [seq(coeff(P,X,n-i),i = 1 .. n)] end proc](imaBCH/DecBCH3.gif)
Le polynome
X
^
n
-1 se décompose sur le corps
F
_{2^
r
}, dont le groupe multiplicatif est celui des racines
n
-èmes de l'unite. Les calculs de décodage vont se faire dans ce corps
F
_{2^
r
}. Pour pouvoir calculer, on va choisir un élément primitif
alpha
(une racine primitive
n
-ème de l'unite). Le polynome minimal de
alpha
est un facteur irréductible du polynome cyclotomique
Phi_n
sur
F
_2, forcément de degré
r
. On produit d'abord la liste de tous les facteurs irréductibles de
Phi_n
sur
F
_2
| > |
Prim:=[op(Factor(numtheory[cyclotomic](n,X)) mod 2)];
|
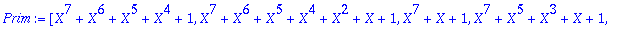
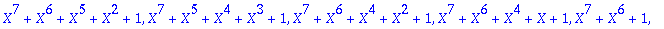
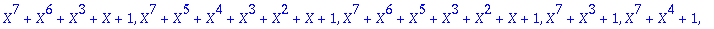
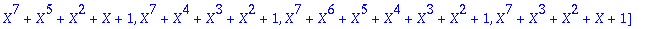
On choisit un facteur
P
de degré
r
dans la liste
Choisir
P
(le polynome minimal de
alpha
)
.
La procédure suivante choisit un
P
avec un nombre minimum de termes de façon à alléger les calculs.
| > |
P:=Prim[1]:
for i from 2 to nops(Prim) do
if nops(Prim[i])<nops(P)then P:= Prim[i] fi
od: P;
|
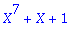
On définit
alpha
comme racine de
P
.
| > |
alias(alpha=RootOf(P));
|
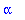
On fixe maintenant la capacité de correction
t
du code BCH (il sera de distance minimum prescrite 2
t
+1).
Choisir
t
pour fixer la capacité de correction du code
.
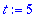
Par définition, un polynme
C
appartiendra au code si et seulement si
C
(
alpha
^
i
)=0 pour
i
=1,...,2
t
. On écrit une procédure qui calcule le polynme générateur du code. C'est le pgcd des polynomes minimaux sur
F
_2 des
alpha
^
i
avec
i
entre 1 et 2
t
. On calcule l'ensemble des facteurs irréductibles de
X
^
n
-1 pour trouver dedans le polynome minimal de
alpha
^
i
avec
i
entre 3 et 2
t
. Pouvez-vous expliquer pourquoi on fait des pas de 2 dans la procédure suivante ? (Se souvenir que si
beta
est racine d'un polynome à coefficients dans
F
_2, alors
beta
^2 l'est aussi.)
| > |
Generateur:=proc(alpha,t,X)
local G, SH, f, i ;
G:= subs(_Z=X,op(alpha)): #recupere le polynome minimal de alpha
SH:={op(Factor(X^n-1) mod 2)} minus {G}:
if t>1 then
for i from 3 by 2 to 2*t-1 do
for f in SH do if Eval(f,X=alpha^i) mod 2 = 0
then G:=G*f : SH:=SH minus {f} : break fi od
od
fi:
Expand(G) mod 2;
end;
|
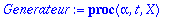
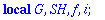
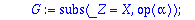
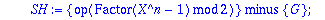

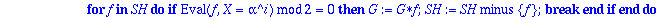


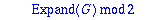

Et voici le polynome générateur du code, et la dimension
d
du code
| > |
G:=sort(Generateur(alpha,t,X)); d:= n-degree(G,X);
|
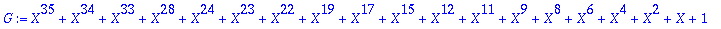
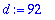
Décodage par l'algorithme d'Euclide
Nous allons maintenant écrire les procédures de l'algorithme de décodage.
On commence par calculer le "polynome syndrome" d'un mot recu
R
de longueur
n
. C'est le polynome
S
_1 +
S
_2
Z
+...+
S
_{2
t
}
Z
^{2
t
-1}, où
S
_
i
=
R
(
alpha
^
i
).
| > |
Syndi:=proc(P,i,alpha)
local beta;
beta:=Normal(alpha^i) mod 2:
Eval(P, X=beta) mod 2;
end;
|
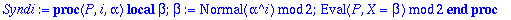
| > |
Syndrome:=proc(R,alpha,t,n,X,Z)
local i,P;
P:=Pol(R,n,X):
add(Syndi(P,i,alpha)*Z^(i-1), i=1..(2*t))
end;
|
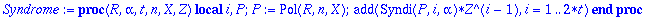
On calcule ensuite le polynome localisateur d'erreurs à partir du polynome syndrome
S
, en utilisant l'algorithme d'Euclide avec
P_
0
= Z
^{2
t
} et
P_
1
= S
et en s'arrétant dès que le degré du reste
P_i
est plus petit que
t.
C'est l'algorithme d'Euclide "semi-étendu": ce qu'on cherche est le
B_i
dans
P_i
=
A_i * Z
^{2
t
} +
B_i
*
S
. Il est donc inutile de calculer
A_i.
Le vrai polynome localisateur d'erreurs est
B_i
/
B_i
(0) (voir Demazure), mais il est inutile de diviser par la constante
B_i
(0) puisqu'on ne s'intéressera qu'aux racines du polynome localisateur d'erreurs.
| > |
Localisateur:=proc(S,t,Z)
local P, Q, R, BB, B, C;
P:=Z^(2*t): Q:=S: BB:=0: B:= 1:
while degree(Q,Z) >= t
do C:=BB-B*Quo(P,Q,Z) mod 2 : R:=Rem(P,Q,Z) mod 2:
P:=Q: Q:=R: BB:=B: B:=C:
od:
Normal(collect(B,Z)) mod 2;
end;
|
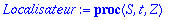
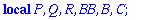
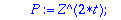
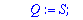
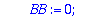
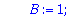




Enfin, la procédure suivante permet de retrouver le vecteur d'erreur à partir du polynome localisateur. Le bit
r_i
du mot recu
R
est erroné si et seulement si
alpha
^
i
est racine du polynome localisateur d'erreurs. (Si on suit le livre de Demazure, ca serait si et seulement si
alpha
^(-
i
) est racine; c'est parce que, contrairement à ce qui est fait ici, Demazure identifie un mot avec un polynome écrit dans le sens des puissances croissantes.)
| > |
Testz:=proc(L,i,alpha,Z)
if Eval(L, Z=alpha^i) mod 2 =0 then 1 else 0 fi;
end;
|
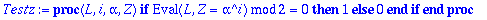
| > |
Erreur:=proc(L,alpha,n,Z)
local i;
[seq(Testz(L,i,alpha,Z),i=1..n)]
end;
|
![Erreur := proc (L, alpha, n, Z) local i; [seq(Testz(L,i,alpha,Z),i = 1 .. n)] end proc](imaBCH/DecBCH36.gif)
Essais
On va passer a des essais. On écrit un générateur de mots de code au hasard. On multiplie le polynome générateur
G
par un polynome au hasard de degré <
d
(la dimension du code).
| > |
Motcode:=proc(G,n,X)
local CC, d;
d:= n-degree(G,X):
CC:=Expand((Randpoly(d-1,X) mod 2) * G) mod 2:
Mot(CC,n,X);
end;
|



On écrit un générateur de vecteur d'erreur aléatoire, en fonction d'un nombre d'erreurs NE. (Le nombre réel d'erreur peut etre moindre si l'on tire au hasard deux fois la meme position d'erreur).
| > |
Bruit:=proc(NE,n,X)
local BB, EXP, i;
EXP:=rand(0..(n-1)):
BB:=add(X^EXP(),i=1..NE) mod 2:
Mot(BB,n,X);
end;
|
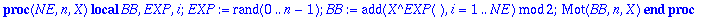
Choisir le nombre d'erreurs
NE.
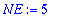
Maintenant on expérimente : on génère un mot de code C au hasard, on y ajoute une erreur aléatoire B, et on passe au décodage. Normalement, si le poids du "bruit" B ajouté lors de la transmission est <=
t,
le décodage est correct.
| > |
C:= Motcode(G,n,X);
B:= Bruit(NE,n,X);
R:=C+B mod 2;
S:=Syndrome(R,alpha,t,n,X,Z);
L:=Localisateur(S,t,Z);
ERR:=Erreur(L,alpha,n,Z);
DECODE:=R+ERR mod 2;
evalb(C=DECODE);
|